Attribute calculation may be done through the Global Mapper interface, by selecting Attribute Calculator from the Layer Menu. The tool can calculate a new attribute value (or update the value for an existing attribute) for features in a layer based on a formula. That formula may use other attributes as operands.
In scripting, the formula calculator is used by the CALC_ATTR_FORMULA command and the DEFINE_VAR command. It allows you to calculate a new value (or update an existing value) based on a formula. In the case of CALC_ATTR_FORMULA, the calculator allows you to calculate new attribute values based on a feature's attributes. In the case of DEFINE_VAR, the calculator allows you to calculate new script variable values. Formulas may combine numbers and strings and either feature attribute references or script variable references. A number of functions are provided to operate on these values.
Many features of the formula calculator are identical when used in the two applications; where different, the difference will be noted below.
Formula reference
Formulas are expressions that can combine strings, numbers and attributes to form a new value. The formula language also includes a number of functions that may be called to manipulate formula values.
The following values may be referenced on there own, or inside of a function or regular expression.
Strings are sequences of characters, delimited by opening and closing quote characters, either single (') or double ("). The opening quote character must match the closing quote character. To include a literal quote character in your formula, you may do so by preceding it with a backslash character (\). You may also directly use a single-quote character inside a double-quote delimited string without escaping it, and vice-verse. To include a literal backslash character in your string (\), precede it with another backslash character. Here are some examples of strings:
- "a string"
- 'another string'
- "double-quote character (\")".
- The calculator would see this as: "double-quote character (")". Conversely, you could also use 'double-quote character (")'
A note on using strings in script files: since parameters in script files are delimited by double quote characters ("), use single quote characters (') to delimit strings in formulas.
Here are some examples of numbers:
- 3.14159
- 42
- 1234e-3 (scientific notation; the result is 1.234)
- 123,456 (European notation; the result is 123.456)
Attributes are named values attached to features. Attribute names may be specified in several ways. For simple attribute names, with no special characters or embedded spaces, the name itself will suffice. For attribute names that have embedded spaces or non alphanumeric characters, you can delimit the name with percent characters (%); similar to strings, to include a % character in your attribute name, precede it with a backslash character (\). And if you wish to use the result of a string expression as an attribute name, then you can use the attr() function to do so.
Note that attribute names are matched in a case-insensitive manner; "ELEVATION" is the same as "elevation". Here are some examples of attribute names:
- ELEVATION
- %color name%
- %\%Count% - the calculator sees the attribute name as %Count
- attr( "ATTRIBUTE" + 5 ) - the calculator sees the name as ATTRIBUTE5
Special attributes are values that are derived from features, but are not proper attributes, for example, feature name, feature's layer name, etc. Special attributes are delimited by the less-than (<) and greater-than (>) characters, respectively. Note that attribute names are matched in a case-insensitive manner; <Feature Name> is the same as <feature name>. These are the special attributes
- <Feature Name> - the display label of the feature
- <Feature Description> - the value is the description of the feature (often the same as the feature type)
- <Feature Desc> - Shortened feature description
- <Feature Layer Name> - the name of the layer that the feature is in
- <Feature Type> - the classification of the feature
- <Index in Layer> - the 0-based index of the feature in the layer that the feature is in
- <Feature Source Filename> - the filename of the layer the feature is in
- <Feature Layer Group Name> - the name of the layer group that the feature is in
Variables are named values defined in a Global Mapper script. Variable names may be specified in two ways. For simple variable names, with no special characters or embedded spaces, the name itself will suffice. If you wish to use a variable that contains embedded spaces, you can use the ATTR function to do so. Note that while feature names are matched in a case-insensitive manner, variable names are case sensitive. "VAR" is not the same variable as "var". Here are some examples of variable names:
- VAR
- attr( 'TIME STAMP' ) - the calculator sees the variable name as "TIME STAMP"
There are a number of predefined variables that you can use in your DEFINE_VAR formulas. These are the special variables:
- SCRIPT_FILENAME - the full path and filename of the running script
- TIMESTAMP - the current date and time in system format
- DATE - the current date in system format
- TIME - current time in system format
- TIME_SINCE_START - the number of seconds since the script starting running
- TIME_SINCE_LAST_LOG - the number of seconds since the last use of this variable
Formulas use various mathematical and logical operators to form a result, similar to spreadsheet formulas. They are (in order of precedence, low-to-high):
- OR : logical OR: both operands are treated as boolean values (see the BOOL() function below), and a boolean value is returned (1 or 0).
- AND : logical AND: both operands are treated as boolean values (see BOOL() function below), and a boolean value is returned (1 or 0).
- =, <>, ~= : comparison operators: equals, not equals, and case-insensitive string comparison, respectively. The = comparison is numeric only if both parameters are numeric; otherwise the comparison is as strings (which is performed in a case-sensitive manner). ~= compares two strings in a case-insensitive manner.
- <, <=, >, >= : relational operators: less than, less than or equal to, greater than, and greater than or equal to, respectively. The comparison is numeric only if both parameters are numeric; otherwise the comparison is as strings.
- +, - : additive operators: plus and minus, respectively. Note that for the '+' operator, if both operands are numeric, then the operation will be numeric addition; otherwise, the operation will be string concatenation. The operands for '-' are assumed to be numeric.
- *, / : multiplicative operators: times and divide, respectively. The operands are assumed to be numeric.
- ^ : exponentiation
- +, -, NOT : unary operators: plus, minus, and logical NOT respectively. The operands for unary plus and minus are assumed to be numeric; the operand for unary NOT is assumed to be boolean.
You may also use parentheses to specify order of operations. In the absence of parentheses, higher precedence operations are performed before lower precedence operations. That is, in the formula "a + b * c", the result is the value of 'a' plus the product of 'b' and 'c' (equivalently "a + (b * c)").
The calculator provides a number of formulas to aid in calculation of values. Note that function names are case-insensitive; e.g., abs is the same as ABS
- LOG( expression ) : Natural logarithm. The expression parameter is assumed to be a numeric value.
- LOG10( expression ) : Base 10 logarithm. The expression parameter is assumed to be a numeric value.
- SQRT( expression ) : Square root. The expression parameter is assumed to be a numeric value.
- MAX( expression list ) : Maximum value of a comma-separated list of parameters.
- MIN( expression list ) : Minimum value of a comma-separated list of parameters.
- ABS( expression ) : Absolute value. The expression parameter is assumed to be a numeric value.
- MOD( expression1, expression2 ) : Floating point remainder. The value returned is the value of the expression "expression1 - i * expression2", where i is the integral value produces by expression1 / expression2. The expression parameters are assumed to be numeric values.
- FLOOR( expression ) : Floor. The largest integer that is less than or equal to expression. The expression parameter is assumed to be a numeric value.
- CEILING( expression ) : Ceiling. The smallest integer that is greater than or equal to expression. The expression parameter is assumed to be a numeric value.
- ROUND( expression ) : Rounding. The integer that is nearest to the expression. The expression parameter is assumed to be a numeric value.
- TRUNCATE( expression ) : Truncation. The nearest integral portion of the expression. The expression parameter is assumed to be a numeric value.
- LEN( expression ) : Return the length of a string.
- LEFT( expression1, expression2 ) : Extract characters from the left side of a string. The first parameter is a string, and the second parameter is a number that specified how many characters are to be extracted.
- RIGHT( expression1, expression2 ) : Extract characters from the right side of a string. The first parameter is a string, and the second parameter is a number that specified how many characters are to be extracted.
- MID( expression1, expression2, expression3 ) : Extract characters from the middle of a string. The first parameter is a string; the second parameter is a number that specified how many characters are to be extracted from the left side of the string; the third parameter is a number that specified how many characters are to be extracted from the right side of the string.
- FIXED( expression1 [, expression2] ) : Formats expression1 as a numeric value, to an optional number of decimal places, specified by expression2, if present; if it's not present, then the default is 2 decimal places.
- RANDOM ( <number>, <number> [, integer] ) : The first number is the lower bound for the numbers generated and the second number is the upper bound. If only integers are desired, then the optional third parameter, 'integer' can be used ). The numbers produced form a closed interval The range defines a closed interval over the bounds, such that values that equal the lower and upper bounds bounds can be returned. The random number generators used produce a uniform distribution over the range.
- CONCAT( expression list ) : Concatenates the comma-separated list of expressions and returns it as a string.
- COMPARE( expression1, expression2 ) : Compares the two expressions as strings in a case-sensitive manner; returns a negative number if the first expression is less than the second expression, a positive number if it's greater, and 0 if they're equal.
- COMPARENOCASE( expression1, expression2 ) : Compares the two expressions as strings in a case-insensitive manner; returns a negative number if the first expression is less than the second expression, a positive number if it's greater, and 0 if they're equal.
- HASPREFIX(expression1, expression2) : Determines if sting has a specified case-sensitive prefix. Return 1 if expression2 exists as a prefix of expression1, return 0 if otherwise.
- HASPREFIXNOCASE(expression1, expression2) : Determines if string has a specified case-insensitive prefix. Return 1 if expression2 exists as a prefix of expression1, return 0 if otherwise.
- MAKEUPPER( expression ) : Convert a string to upper case.
- MAKELOWER( expression ) : Convert a string to lower case.
- MAKEMIXED (expression): Convert a string to mixed case (uppercase first letter only).
- NUM( expression ) : Convert to numeric value
- STR( expression ) : Convert to string value
- BOOL( expression ) : Convert to boolean value, either 1 or 0. For numeric values, a non-zero value converts to 1, and a zero value to 0. For strings, values of "true", "t", "yes", "y", and "1" (case-insensitive) all convert to 1, while any other value converts to 0.
- ATTR( expression ) : Treat as attribute or variable name; the result of the expression is treated as an attribute name in the CALC_ATTR_FORMULA command, or as a variable name in the DEFINE_VAR command
- EXISTS( name ) : Returns 1 (true) if the named attribute or variable is defined, and 0 (false) otherwise. Note that the name parameter must be either an attribute or variable name, or a single string that contains the name of the attribute or variable; string expressions (e.g. "abc" + "123") are not allowed.
- ISNUM( expression ) : Return true if the string denotes a valid number, and false otherwise.
- IF( expression, expression2, expression3 ) : Evaluate expression, and if it is true, return expression2; otherwise return expression3
- MATCH( expression1, expression2 ) : Determine whether the first expression matches the regular expression designated by the second expression, and if so, return 1 (true); otherwise, return 0 (false).
- REPLACE( expression1, expression2, expression3 ) : Replace any substrings in the first expression that match the regular expression designated by the second expression with the text of the third expression. If no matches are found, then the result is the original string.
- SEARCH( expression1, expression2 ) : Return the first substring from the first expression that matches the regular expression designated by the second expression. If no match is found, then the result is an empty string.
- FIND( expression1, expression2 ) : Return the 0-based index substring of the first expression that matches the regular expression designated by the second expression. If no match is found, then -1 is returned.
- CLIP( expression, expression2, expression3 ) : Return a substring from the first expression, whose beginning is delimited by one of the characters from expression2, and whose end is delimited by one of the characters from expression3. That is, the function reads the first string until it encounters a character from the second string, and then reads on until it encounters a character from the third string, and returns the characters between (not including the delimiter characters).
- SIN( expression ) : Return the sine of an expression, assumed to be expressed in radians.
- COS( expression ) : Return the cosine of an expression, assumed to be expressed in radians.
- TAN( expression ) : Return the Tangent of an expression, assumed to be expressed in radians.
- ASIN( expression ) : Return the arc sine of an expression, assumed to be expressed in radians.
- ACOS( expression ) : Return the arc cosine of an expression, assumed to be expressed in radians.
- ATAN( expression ) : Return the arc tangent of an expression, assumed to be expressed in radians.
- DEGTORAD( expression ) : Convert the expression, assumed to be decimal degrees, to radians.
- RADTODEG( expression ) : Convert the expression, assumed to be radians, to decimal degrees.
- RADTODEG( expression ) : Convert the expression, assumed to be radians, to decimal degrees.
- PI : The constant PI (3.14159...).
- calculateArea( [units]): Returns the area of an area feature, in the units specified inside the parenthesis. If the feature is not an area, then 0 is returned. If no unit is specified the default is meters. Other acceptable unit values are:
- "default" : default units for the layer
- "feet", "ft" : feet
- "meters", "m" : meters
- "miles" : miles
- "kilometers", "km" : kilometers
- calculateLength( [units]): returns the length of a line feature or the perimeter of an area feature in the given units, If the feature is neither an area or a line, then 0 is returned. Acceptable unit values are the same as above.
- isvalid(): returns 1 if the feature is a line or an area that is not self-intersecting, and 0 otherwise.
- isArea(): returns 1 if the feature is an area feature, and 0 otherwise.
- isLine(): returns 1 if the feature is a line feature, and 0 otherwise.
- isPoint(): returns 1 if the feature is a point feature, and 0 otherwise.
- isLidarPoint(): returns 1 if the feature is a Lidar point, and 0 otherwise.
- isSelected(): returns 1 if the feature is currently selected, and 0 otherwise.
- isDeleted():returns 1 if the feature is currently marked as deleted, and 0 otherwise.
- isModified(): returns 1 if the feature is currently marked as modified, and 0 otherwise.
- @count(string): Returns the count of non-empty values in the layer for the given attribute. This is how many features in the layer have a value entered for the specified attribute. The result will be the same for all features in the layer.
- @countNumeric(string): Returns the count of features in the layer that contain a numeric value for the specified attribute.
- @countEmpty(string): Returns the count of empty values in the layer for the given attribute. This is how many features in the layer have an empty/ null value for the attribute specified in parenthesis. The result will be the same for every feature in the layer.
- @sum(string): Returns the sum of (numeric) values in the layer for the given attribute.
- @min(string): Returns the minimum value of all the numeric values in the layer for the specified attribute.
- @max(string): Returns the maximum value of all the numeric values in the layer for the attribute specified in parenthesis.
- @average(string): Returns the average value of all the numeric values in the layer for the given attribute.
- @median(string): Returns the median value of all the numeric values in the layer for the given attribute.
- @stddev(string): Returns the standard deviation among the numeric values in the layer for the given attribute.
- @variance(string): Returns the variance among the numeric values in the layer for the given attribute.
Note: The @ functions look at every unique geometry in a layer, and therefore count the values of grouped multi-part features multiple times. See also Calculate Statistics for Attribute Values
Regular expressions are used in the MATCH, SEARCH, REPLACE, and FIND functions. Regular expressions allow a very rich and powerful set of capabilities for performing pattern matching in strings. Regular expressions in Global Mapper are specified using a modified version of the ECMAScript regular expression language, documented here: Modified ECMAScript regular expression grammar.
Example: Assume that the attribute "DLG3CODEPAIR is the string "120,250". Some examples:
- The function match(DLG3CODEPAIR, "\d*,\d*") specifies a regular expression that is zero or more digits, followed by a comma, followed by zero or more digits. Consequently, the match function would return 1.
- The function search(DLG3CODEPAIR, "\d*") specifies a regular expression that is zero or more digits. Consequently, the search function would return the string "120".
- The function search(DLG3CODEPAIR, ",\d*") specifies a regular expression that is a comma followed by zero or more digits. Consequently, the search function would return the string ",250".
- The function replace(DLG3CODEPAIR, "\d*,", "10" + ",") specifies a regular expression that is zero or more digits followed by a comma. Consequently, the replace function would return the string "10,250".
Note that the SEARCH function only returns the first match in the string (if any); there is no facility for returning further matches.
The third parameter of the REPLACE function is the replacement string. The replacement string allows you to specify literal characters as the replacement for the match pattern, but you may also use the following special sequences to specify other replacements:
- $n - The n-th backreference (i.e., a copy of the n-th matched group specified with parentheses in the regex pattern). n must be an integer value designating a valid backreference, greater than 0, and of two digits at most. E.g., '$2' specifies the second parenthesis-specified group in the match pattern.
- $& - A copy of the entire match
- $` - The prefix (i.e., the part of the target sequence that precedes the match).
- $´ - The suffix (i.e., the part of the target sequence that follows the match).
- $$ - A single $ character.
The calculation mode may be set in the Calc Attribute Setup dialog, or as a parameter to the CALC_ATTR_FORMULA. It is important to understand the rules when using attribute values in conjunction with literal values (numbers and strings)
Although attributes are fundamentally strings, we may use them to represent numbers, and that can cause ambiguity in formulas, since the operation may equally be applicable if the attributes are treated as strings or numbers, so the calculator needs to know how to interpret them.
To guide the formula calculator in these circumstances, the user can choose one of several calculation modes: automatic, numeric, or string.
In automatic mode, the default, for operations like comparison ('=', '<>'), relational ('<', '<=', '>', '>=') or addition ('+'), the calculation is performed based on the type of the first operand.
For numeric mode, the calculation is performed as if its arguments were numeric. For string mode, the calculation is performed as string.
In many cases, conversions are performed automatically; for example, when a string expression is expected in a function parameter, a conversion from numeric type is performed. If required, there are functions to turn an expression into one or the other data type; see the NUM, STR, and BOOL functions below. For example, if the calculation mode is automatic, then we can force ELEVATION to be treated as a number by using the NUM function: "num(ELEVATION) + 100"
When using a string as a number, conversions are not guaranteed, particularly string-to-numeric conversions (for example, converting the string "four" to a number would give the result 0); these are generally ignored in the calculator. If you want to be certain that a string contains a number, you can use the ISNUM function to verify it.
The ELEVATION attribute typically denotes a numeric value. Suppose that its value is "1203.47". Consider the formula "ELEVATION + 100". The result is dependent on how the ELEVATION term is interpreted:
-
Calculation mode: Automatic
Since ELEVATION is considered to be a string, this will be a string concatenation operation, with result "1203.47100"
-
Calculation mode: Numeric
ELEVATION can successfully be treated as a number, so the result is "1303.47"
-
Calculation mode: String
ELEVATION is treated as a string, so the result is "1203.47100"
Conversely, consider the formula "100 + ELEVATION":
-
Calculation mode: Automatic
ELEVATION can successfully be treated as a number, so the result is "1303.47"
-
Calculation mode: Numeric
ELEVATION can successfully be treated as a number, so the result is "1303.47"
-
Calculation mode: String
ELEVATION is treated as a string, so the result is "1203.47100"
Classify values
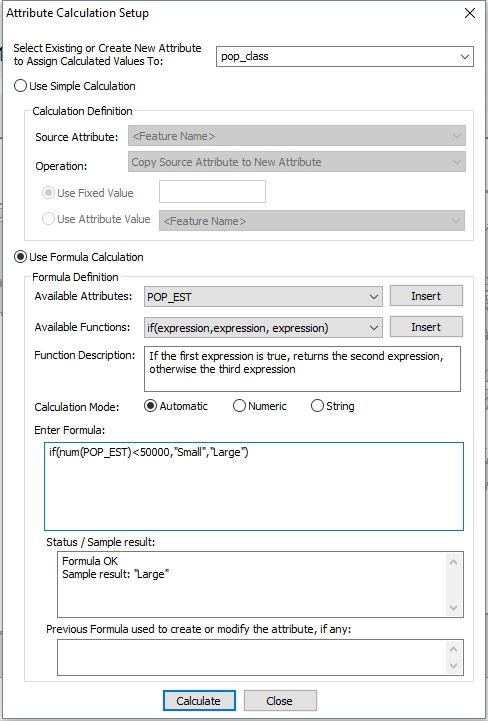
This example categorizes population values into two groups, large and small. This was performed on the default country data, that can be loaded by pressing the Load Default Data button on the Global Mapper start screen. Features with a population estimate attribute below 50,000 will get the Small attribute value, and all other will get a value of Large.
The values will go into the new attribute pop_class specified at the top of the dialog .
The formula below may be built using the insert buttons for the functions and attributes, or typed manually.
if(num(POP_EST)<50000,"Small","Large")
This means that if the population estimate attribute (POP_EST) value is less than 50,000 the new attribute value will be Small. Otherwise, if it is not less than 50,000, the value will be Large.
Concatenate Text
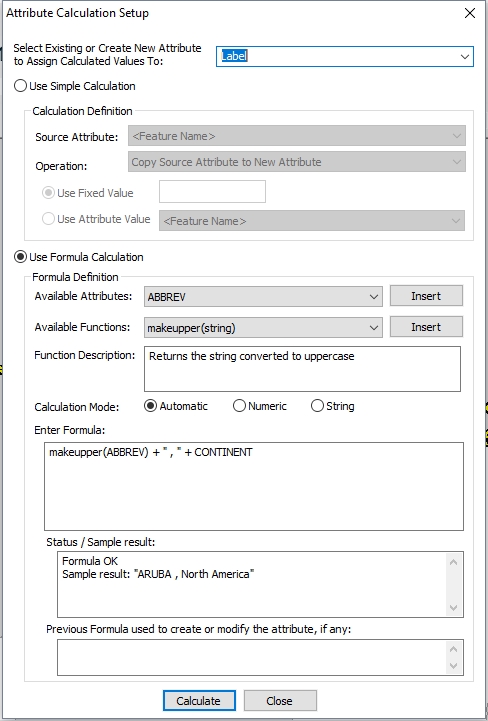
This example combines the country and continent name together, with a spaces and a comma between. This was done with the default country data. It also converts the country name to all uppercase letters. The calculated values will be places in a new attribute named Label.
The following formula is used:
makeupper(ABBREV) + " , " + CONTINENT
The sample result window shows the example attribute result of:
ARUBA, North America
Note that the examples that follow are of attribute formulas; equivalent script formulas would be very similar, but would refer to script variables rather than feature attributes.
Here is a sample of creating a new elevation attribute in feet from an elevation attribute (ELEV_M) in meters, including an appended unit string.
GLOBAL_MAPPER_SCRIPT VERSION=1.00
// Create new ELEV_FT attribute with attribute in feet in any loaded layers
CALC_ATTR_FORMULA NEW_ATTR="ELEV_FT" FORMULA="ELEV_MT * 3.2808"
// Append the unit name to the new attribute
CALC_ATTR_FORMULA NEW_ATTR="ELEV_FT" FORMULA="ELEV_FT + ' ft'"
Here is a sample of some text manipulation using various string and regular expression functions. Assume that the feature set has an attribute named DLG3CODEPAIR that is a string formatted in the form of a comma-separated pair of numbers, e.g. "123,456" (this is the familiar USGS Digital Line Graph major/minor code pair). To implement a script that pulls these numbers out as individual attributes, you could use the clip() function:
GLOBAL_MAPPER_SCRIPT VERSION=1.00
// Create new separate DLG code attributes
CALC_ATTR_FORMULA NEW_ATTR="DLGCodeMajor" FORMULA="clip( DLG3CODEPAIR, '', ',' )"
CALC_ATTR_FORMULA NEW_ATTR="DLGCodeMinor" FORMULA="clip( DLG3CODEPAIR, ',', '' )"
Alternately, you could use regular expressions: '\d' is any digit, '+' means match one or more of the previous pattern, and '$' means match the end of the source string:
GLOBAL_MAPPER_SCRIPT VERSION=1.00
// Create new separate DLG code attributes
CALC_ATTR_FORMULA NEW_ATTR="DLGCodeMajor" FORMULA="search( DLG3CODEPAIR, '\d+' )"
CALC_ATTR_FORMULA NEW_ATTR="DLGCodeMinor" FORMULA="search( DLG3CODEPAIR, '\d+$' )"
To create a new attribute that indicates whether the DLG code pair attribute exists and is valid::
GLOBAL_MAPPER_SCRIPT VERSION=1.00
// Create new attribute indicating DLG code pair exists and is valid
CALC_ATTR_FORMULA NEW_ATTR="DLGCodeValid" FORMULA="if( exists(DLG3CODEPAIR) and match(DLG3CODEPAIR,'\d+,\d+'), 'VALID', INVALID' )"
Here is a further example of text manipulation using the regular expression 'replace' function. Assume that the above feature set is known to contain DLG3CODEPAIR values that contain various problems in formatting, perhaps caused by user input errors. Although the standard format is described by the regular expression "\d+,\d+", actual values may contain extra spaces before or after the numbers, or the comma separator is not used or some other character, say ';' was entered. We'd like to tidy these values up so that they match the correct format. One way to do it might be to use a series of simple formulas to clean up the incorrect values. But the REPLACE function has some powerful features that can be used to fix these sorts of problems.
First, let's define a regular expression that describes the above problems:
'^ *(\d+) *(,|;)? *(\d+) *$'
This says: first try to match any space characters, followed by one or more digits, followed by some spaces, optionally followed by either ',' or ';', followed by some spaces, followed by one or more digits, followed by some spaces.
Note the use of parentheses to designate sub-patterns in the main pattern. This allows us to group smaller patterns so that we can express things like 'optional comma or semicolon' ('(,|;)?') easily, but more importantly, for the REPLACE function, it allows us to identify sub-patterns to the replacement parameter. In the replacement parameter, sub-patterns in the regular expression parameter are referenced using '$1', '$2', and so on. So in our example, the first digit string pattern is identified as '$1', the optional separator is identified as '$2', and the second digit string is identified by '$3'.
Therefore, to get what we want, we would specify the replacement parameter as '$1,$3', meaning the first digit string, followed by a comma, followed by the second digit string. The resultant script command would be as follows (omitting any validation of the attribute existence):
GLOBAL_MAPPER_SCRIPT VERSION=1.00
// Clean up DLG code pair attribute errors
CALC_ATTR_FORMULA NEW_ATTR="DLG3CODEPAIR" FORMULA="replace( DLG3CODEPAIR, ' *(\d+) *(,|;)? *(\d+) *', '$1,$3' )"