
Join a table to existing vector data using a common field or column to match on using the Join tool.
To join a table, press the Join Attributes button in the Attribute Editor, or from the layer menu choose Join Attribute Table/File to Layer. This tool also available by right-clicking on the layer in the Control Center and going to the Layer submenu, then select JOIN- Join Attribute Table/File to Layer
The data in this example table join comes from the World Bank.
https://data.worldbank.org/data-catalog/ed-stats
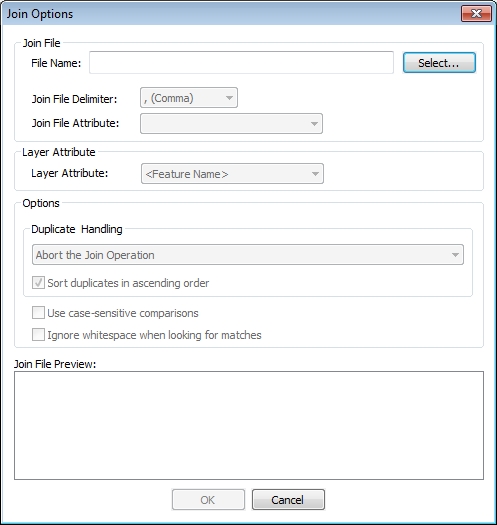
Join File
File Name
-
File Name — Choose the table to join. Supported formats include simple ascii text files such as csv, txt, and dbf. Version 22.1 and later also supports *.xls and *.xlsx files.
-
Join File Delimiter — Specify the delimiter used in the file to separate values. If the join file is a DBF, this field is not applicable, and will be disabled.
-
Join File Attribute — Select the name of the attribute that matches an attribute in the existing layer. This is sometimes referred to as the Foreign Key or Common Attribute. The attribute names come from the first row of the table.
-
Attributes to Copy — Put a check next to each attribute to be copied, or remove the check to prevent an attribute from being copied. By default, all attribute names are selected. At least one attribute must be selected to join.
Click the Select All button to restore the check next to all of the attributes. Click the Clear All button to remove the check from all attributes.
Layer Attribute
Options
Duplicate Handling
When duplicate records are found there is a prompt providing options for handling the duplicate values:
- Abort the join — cancel the join operation
- Keep Attributes From Last Record Matching Join Attribute— keep the attribute values from the last matching record in the join file
- Keep Attributes From First Record Matching Join Attribute — keep the attribute values from the first matching record in the join file
- Keep All Matching Records, Append Values to End of Attribute — keep all matching records from the join file, appending new values to the existing attribute with a comma separator. For example if the table had one matching record with a value of Mike and another matching record with a value of Sam, the resulting joined table would have a value of "Mike, Sam".
- Keep All Matching Records, Append Values to End of Attribute, Sorted — keep all matching records from the join file, appending new values to the existing attribute with a comma separator. See below for the sort order.
- Sort duplicates in ascending order — this will be enabled when the sorted option is chosen from the list. When checked, the list of duplicate attributes values will be sorted in ascending order. If it is not checked, the sort will be in descending order.
- Keep All Matching Records in New Attribute Names — keep all matching records from the join file, but create new attribute values with a numeric suffix for the multiple entries. For example if there were 5 matching records with an ADDR attribute, you would get ADDR, ADDR2, ADDR3, ADDR4, and ADDR5 attributes added
- Duplicate Feature for Each Duplicate Join Attribute — create duplicate features for each record with a duplicate join attribute, one addition feature for each duplicate join attribute value.
Use case-sensitive comparisons — specifies whether or not text comparisons are case sensitive or not. Check this option to enable. By default comparisons are not case sensitive.
Ignore whitespace when looking for matches— specifies whether or not whitespace (i.e. spaces and tabs) should be ignored when looking for matches to join on. Check this option to ignore whitespace. By default whitespace is considered.
Join File Preview
The preview at the bottom of the dialog shows an example of the external table that will be added to the vector features.